
| My Research Interests |
|



- T-Codes are variable-length codes. They can be used in a similar fashion as Huffman codes. I.e., you can use short codewords from a T-Code set to encode the frequently occurring symbols of an information source, and the longer codewords to encode the less frequent symbols.
- T-Codes are highly self-synchronizing. That is, if the transmitted stream of T-Code codewords is subjected to noise or other forms of corruption, a T-Code decoder will usually regain synchronization automatically (i.e., find out where the codeword boundaries are). This process is very well explained. The decoder can even derive its own synchronization status if it knows how many of the previous bits were received correctly.
- By the way - you can also use other things than just bits - T-Codes can be constructed from any finite alphabet.
- The construction of T-Codes is done via a recursive copy-and-append process called T-augmentation. The animation below shows an example: every alphabet is a T-Code set. T-Code sets are derived from other T-Code sets by choosing a T-prefix p and a positive integer k called the T-expansion parameter (or copy-exponent). The tree of the old T-Code set is copied k and the copies are linked to the original and each other through node p. This process may be repeated an arbitrary number of times to generate arbitrarily large sets.
- T-Codes were invented by Mark Titchener, who was my PhD supervisor.
- Want to know more? Download my PhD thesis as gzipped PS or PDF.
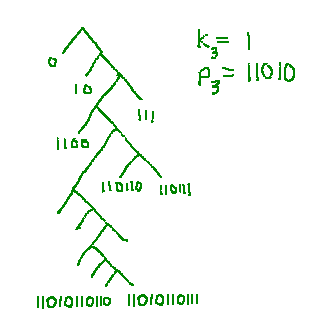 The animation above shows (if you've got JavaScript enabled) three successive T-augmentations of the binary alphabet to yield a T-Code set with 13 codewords.
|
- T-information theory is based on a duality between T-Code sets and finite strings
- The longest codewords in each T-Code set are unique, i.e., there is no other T-Code set that has the same strings as longest codewords. This was discovered experimentally by Mark Titchener. The proof was furnished by Radu Nicolescu.
- For every finite string, there is exactly one T-Code set for which it is a longest codeword.
- The longest codewords in a particular T-Code set are identical except for the last symbol. They contain, in order, all the k copies of each T-prefix p.
- Given a string, it is always possible to derive the associated T-Code set. This is done in an algorithm called T-decomposition. T-decomposition decodes a string at multiple levels of T-augmentation and thus extracts the T-prefixes.
- Thus, T-augmentation can be seen as a string production algorithm as well as a code set production algorithm. In the string view, T-decomposition may be seen as an algorithm that removes codeword boundaries in a hierarchical order. At each level, the codeword boundaries following the T-prefix for that level are removed. At the top level, no boundaries are left - the string decodes as a single codeword. This is demonstrated on the right.
- The T-expansion parameters extracted from the string yield the T-complexity CT :
CT = log2(k1 + 1) + log2(k2 + 1) + ... - The T-complexity permits the derivation of a T-information measure (basically, the inverse logarithmic integral of the T-complexity), which in turn gives rise to a T-entropy (first derivative of the T-information with respect to the string length). These seem to be sensitive instruments for the measurement of information in strings and seem to be closely related to the Lempel-Ziv production complexity.
- Applications: screeds! I've worked on similarity measures (with my PhD student Yang Jia, completed 2005), network event detection (with my PhD student Raimund Eimann, completed 2008), and currently use it to ascertain whether packet trains on the Internet will continue to arrive in sufficiently nice shape to allow us to use real-time applications such as VoIP telephony in future (joint work with my current PhD student 'Etuate Cocker and collaborators in almost a dozen other countries around the Pacific and beyond). I'm also looking into using it for heart sound classfication with colleagues from the University of Macau. And that's just the start...
- Looking for an easy-to-use tool to compute T-complexity, T-information, and T-entropy? Niko Rebenich's Masters project at the University of Victoria resulted in FLOTT, an efficient implementation of the fundamental ftd algorithm Yang Jia and I published in 2005.

| slower | faster |
- Can we improve Internet access in satellite-connected Pacific islands with network coding? Read and view more here.
- Could the Internet hang up on us? Together with my PhD student 'Etuate Cocker, I've instigated the International Internet Beacon Experiment (IIBEX), which we're coordinating from here in Auckland. Together with colleagues in well over a dozen countries around the world,
we're trying to find out whether the fast growth of the net threatens its ability to function, in particular when it comes to real-time traffic such as Voice over IP. T-entropy helps us tell the difference between
jitter that's caused by packets sitting in router queues of unpredictable length, and packets arriving out of sync via several alternative paths. The project got kick-started by a 2012 Faculty of Science
Research Development Fund grant.
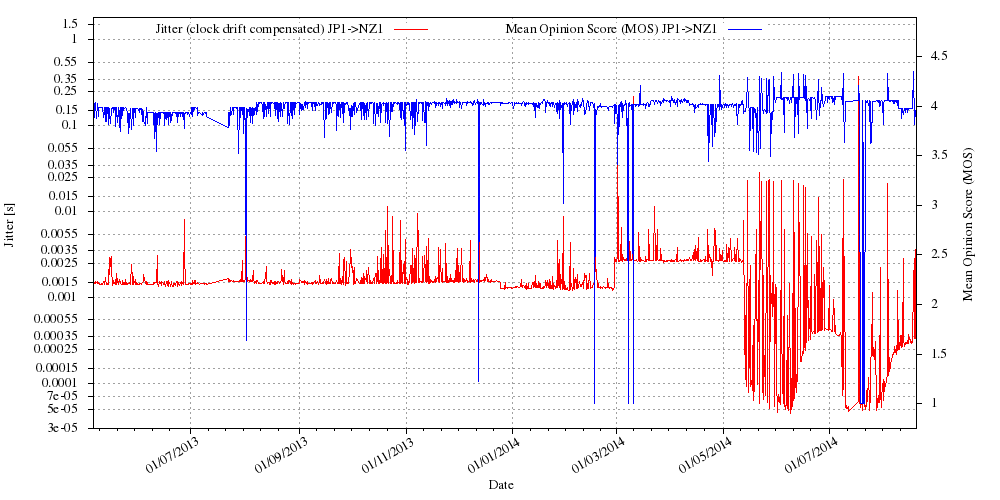
IIBEX measurement path between the beacon at the University of Tokyo and one of ours here in Auckland, showing estimated Mean Opionion Score and jitter. Note how jitter and MOS become less predictable and MOS drops down to call drop level? Get a live plot of this and hundreds of other paths on the IIBEX website
- Could network-coded TCP help us improve Internet access in remote locations such Pacific Island nations that can only connect via expensive narrowband satellite links? We're investigating
this with the help of ISIF Asia/PICISOC and Internet NZ in a
collaboration with colleagues at Muriel Médard's Network Coding and Reliable Communications Group at MIT. At this point (August 2014), we're waiting
for equipment to arrive so we can start deploying. The IIBEX beacon network will help us observe the performance of the test links. Watch our project lauch video for ISIF on YouTube.
- I'm always trying to push the boundaries on T-codes and T-information theory a little. For example, is there a more elegant algorithm to match T-codes to a given source, like Huffman's algorithm for Huffman codes perhaps?
Can we find a closed-form expression for the maximal T-complexity of strings of a given length that's not asymptotic? Are there other applications for T-codes and T-decomposition in
error correction, encryption, or in data compression? This is ongoing work with a number of people, including Aaron Gulliver and Niko Rebenich from the University of Victoria, Ludwig
Staiger from the University of Halle-Wittenberg in Germany, as well as Mark Titchener and Radu Nicolescu here in Auckland.
- Can we use T-information theory to improve the automatic diagnosis of heart conditions based on heart sound (auscultation)? I work on this with Ming-Chui Dong and Booma Devi Sekar at the University of Macau (see above). At this point, we're trying to scrape enough reliable sound data together, and will have Lixin Yang join us from Singapore shortly to assist in this.
My involvement here was really born out of annoyance. I think it's nice to be able to register for a scientific conference via the conference's web site - no messy faxes etc. So I set up a number of CGI-based online participant registration systems for various conferences we held here, including DMTCS'96, UMC'98, IVCNZ'98, and ACSW'99. Problem was - each conference looked different, so each system was different, too. The information we were collecting was different, the rules didn't match, and the conference structures weren't alike. About a week's worth of work to write a new site each time, considerably more for ACSW'99... But one learns lessons along the way, too - valuable ones.
After ACSW'99, Radu Nicolescu suggested that we get two students to work on a more universal system. They soon found out that this wasn't a simple task. The two hardly got beyond a case study of what would be involved in the setup of a site and the rudimentary database structure. One of them, Sudhir Reddy, stayed on as a MSc student and developed a system that has since served two further conferences, UMC2K in Brussels and ROBVIS01 in Auckland. It's still somewhat cumbersome to drive and doesn't yet have all the nice features we want. But the benefits are already visible - re-rigging a copy of the UMC2K site to ROBVIS01 took less than two days, and most of that was spent finding out what information and options were needed. Currently, the site is used for DMCTS01, a conference organised jointly between CDMTCS in Auckland and the Ovidius University of Constantza, Romania.
- Frame-based web site with a navigation menu on the left, a central content frame, and a title frame at the top, plus a small control frame at the bottom. No, it doesn't look quite as ugly as some of the frame-based sites you'll see elsewhere.
- Prospective participants can browse the web site to find out what the conference is all about. They can also optionally subscribe to a mailing list, if there is one.
- There's an online paper submission facility which we've never been asked for, so we don't know whether it really works...
- As registration time comes, the prospective participants can register via an easy-to-use registration wizard - my pride and joy.
|
| A screenshot of the personal info page of the registration wizard we used for UMC2K. |
What else is planned for the future?
- Shift more of the guts to the client side - it speeds things up if you don't have to go back to the server each time. Did you know that every HTTP request to a server on the other side of the world takes about half a second to complete, even if the server responds instantaneously?
- Give the files of the project more meaningful names. Probably the most urgent project.
- Assemble a proper distribution with documentation, so we don't have to set it up for all and sundry.
- Make the organiser's view more userfriendly and provide more avenues for tailored import/export.
- Add additional modules for accommodation, paper submission and refereeing, arrival information, etc.
 It's no secret that I am a great fan of JavaScript Applications. I even translated an entire book on the topic from English to German, for O'Reilly Associates (the publishers that put all the cute animals on their book covers).
It's no secret that I am a great fan of JavaScript Applications. I even translated an entire book on the topic from English to German, for O'Reilly Associates (the publishers that put all the cute animals on their book covers). The book is by Jerry Bradenbaugh, and it's given me a lot of inspiration. There are plenty of JavaScript resources on his site (www.serve.com/hotsyte).
|
JavaScript Application Gallery
|

I'm involved with this through the New Zealand Tourism Research Institute (TRI). The basic idea here is to promote the use of IT in communities through the provision of applications to which the communities involved can contribute as a community effort. The aim is to give communities tangible rewards (e.g., an increased influx of tourists) in order to entice their IT development. More soon.
OK, so you're looking for my PhD thesis or a paper of mine? No worries, they're right here.
I'm happy to talk to you about supervising your undergraduate, graduate, BTech, MSc, PhD, etc. project. If you already have a project idea, just e-mail me and we'll see how we can get it underway. If you're not quite sure yet, there's a number of suggested project topics right here. Have a look and see whether there's one that interests you.