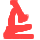| Research |
|
|||||
|
|
||||||
|
|
||||||||||
|
||||||||||
In 2002, I was seconded to the University of the South Pacific for a few weeks to teach Internet programming to students and staff. At the time, Fiji's Internet connection was a rather inadequate satellite link. The Southern Cross Cable had just been laid, but politics had it that there was no connection to. So I put up with hitting "Get Mail" on my laptop as I got into the office and, come lunchtime a few hours later, have at least some of my e-mails. I later got to experience the joys of satellite Internet in the Pacific in Tonga and Samoa, where nations with populations into the hundreds of thousands had to share satellite links with at best a couple of dozen Mbit/s capacity.
In 2011, 'Etuate Cocker started a PhD with me. As a Tongan, he had a personal interest in documenting and improving connectivity in the Pacific. Together (and with the help of a lot of colleagues literally around the world), we built the IIBEX beacon network, which documented rather clearly the quality of connectivity available in satellite-connected places such as (then) Tonga, Niue, Tuvalu or the Cook Islands. We were able to document the improvements seen when islands connected to fibre or upgraded their satellite connection. Still, it became clear that a fibre connection would likely stay literally out of reach for a number of islands, where small population / GDP and remoteness conspire against any business case.

At around the same time 'Etuate started, I became aware of the work by Muriel Médard and colleagues on network coding and TCP. This seemed like a way of dealing with at least some of the packet loss on satellite links, and so we conferred with Muriel: The idea of network coding the Pacific was born. Maybe we could do something to add value to satellite links. Muriel linked us with Steinwurf, a Danish company she had co-founded - they had the software we needed (well, more or less).
With the help of PICISOC, ISIF Asia and Internet NZ, we went out to four islands in the Pacific: Rarotonga (Cook Islands), Niue, Funafuti (Tuvalu), and eventually to Aitutaki (Cook Islands) to deploy network coding gear (mainly consisting of an encoder/decoder machine, and in Aitutaki and Rarotonga also of a small network with two Intel NUCs each). Our respective local partners were Telecom Cook Islands (now Bluesky), Internet Niue and Tuvalu Telecom.
Off-island, we have an encoder/decoder at the University of Auckland and also at the San Diego Supercomputer Centre (SDSC).


Péter Vingelmann from Steinwurf chipped in and not only provided us with exactly the software we needed, but also accompanied us via Skype during the deployments. He works remotely from Hungary, which for him meant absolutely ungodly hours! The software we now use encodes any IP packet arriving at the encoder destined for a host on the other side of the link. More specifically, it takes a number of incoming IP packets and replaces them with a larger number of coded UDP packets, which are then sent to the decoder on the other side of the link, which recovers the original IP packets. So we really code everything: ICMP, UDP, TCP - but it is the TCP where coding really makes a difference.
One of the first insights was that no site is quite like the other: Rarotonga and Aitutaki are both supplied by O3b medium earth orbit satellites. In 2015, neither island quite managed to utilise all of its respective satellite bandwidth. In 2015, Aitutaki had just recently upgraded to O3b and "inofficially" had more bandwidth available than we assumed - thanks probably due to O3b quietly throwing spare bandwidth at the link. Its local access network was awaiting a variety of upgrades, so there simply wasn't enough local demand on the link. Being on a Telecom Wifi hotspot, I had one of the best Internet connections I've ever had in the Pacific. Lucky Aitutaki! Network coding offered no gain here - the problem it solves simply didn't exist here.

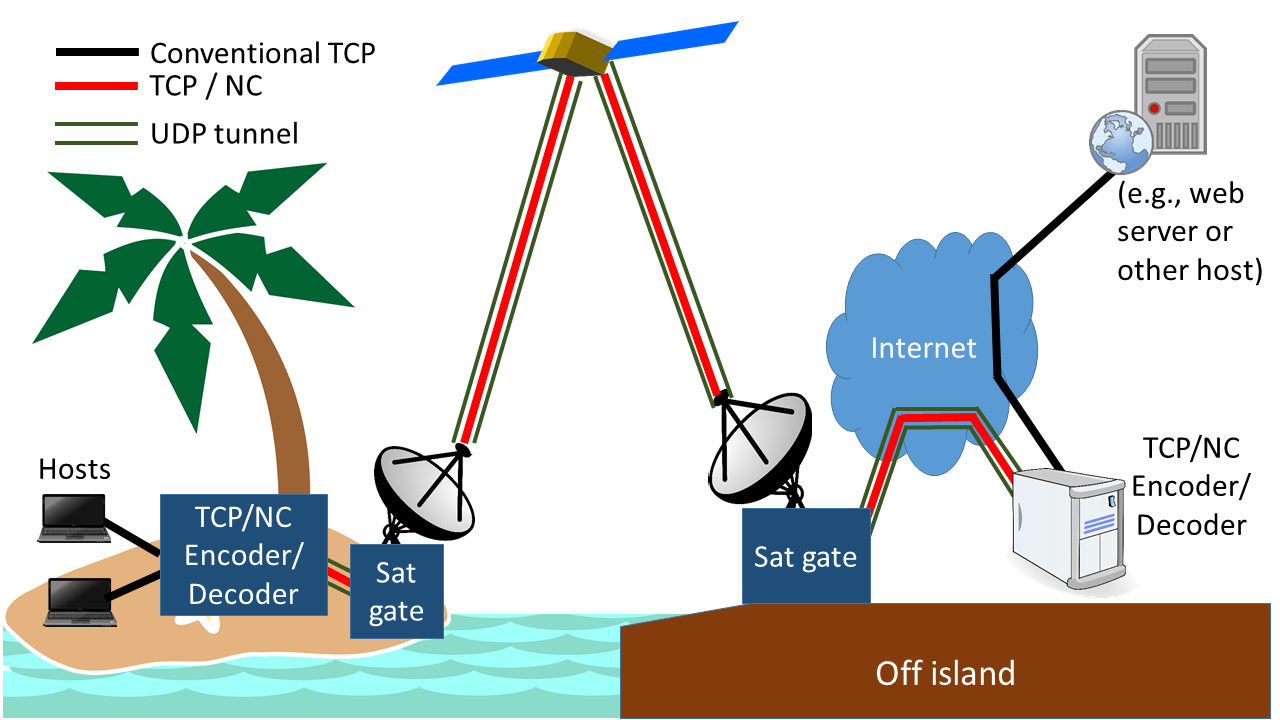
In the case of Rarotonga, which we had visited earlier, it had been an altogether different story: The link there had more bandwidth, but the demand was also much higher, causing severe TCP queue oscillation at peak times (see my APNIC technical blog on queue oscillation or watch me talk about queue oscillation on the APNIC YouTube feed with some cool graphics from APNIC thrown in). How could we tell? Quite simple: Packet loss increases during peak hours, but link utilisation stays capped well below capacity. That happens when the input queue to the satellite link overflows some of the time but clears at others. Here, the network coding gave us significant gains, especially after Péter made the overhead adaptive. With coding, peak time downloads were typically at least twice as fast - and sometimes much more than that.
In Niue, which was on 8 Mbps inbound geostationary capacity at the time, packet loss was significant, but link utilisation was high, meaning that short TCP flows kept the input queue to the satellite link well filled. In scenarios such as these, coding TCP can give individual connections a leg up over conventional TCP. This was the case in Niue as well. However, as practically all of the traffic represents goodput, this comes at the expense of conventional TCP connections, and so becomes a question of protocol fairness. Internet Niue subsequently doubled its inbound capacity, and now looks more like Aitutaki when left alone, but recent experiments suggest that it doesn't take a lot of extra traffic to trigger TCP queue oscillation.
In Tuvalu, we saw once again a combination of low link utilisation and high packet loss, and again coding allowed us to obtain higher data rates. In fact, in some cases, conventional TCP fared so badly that only coded TCP allowed us to complete the test downloads.
Clearly, TCP queue oscillation plays a significant role in underperforming links. This came somewhat as a surprise given that TCP queue oscillation as a phenomenon has been known since people first sent TCP traffic over satellite links. Moreover, it had been considered solved. Clearly, TCP stacks had evolved to cope with this, right?
Well, yes and no. The answer really lies in the history of satellite Internet. Firstly, early satellite connections in the 1980s and early 90s were dedicated point-to-point connections, which generally carried few parallel TCP sessions for very few hosts. In Rarotonga, we see queue oscillation only at times when there are over 2000 parallel inbound TCP flows.
Moreover, the networks connected at either end were generally not that fast at the time (10 Mbps Ethernet was considered state of the art back then), so the satellite links were less of a bottleneck than they are today: If you're having to pare down from 1 Gbps to a couple of hundred Mbps or even just a few Mbps, there are quite a few more Mbps that you potentially have to drop.
In the 1990s, the Internet became a commodity and entire countries connected via satellite. However, in many cases (such as NZ), hundreds of thousands of users made for business cases that allowed for satellite capacities in the order of the capacity of the networks connected at either end. This more or less removed the bottleneck effect. No bottleneck, no TCP queue oscillation.
This leaves the islands: If the demand on an island falls into a bracket where it can only afford satellite capacity that represents a bottleneck, but the demand is large enough to generate a significant number of parallel TCP sessions, then TCP queue oscillation rears its ugly head. Add cruise ships, large drilling platforms and remote communities to the list.
So we know that coding can make individual TCP connections run faster when there's TCP queue oscillation. But what about other techniques? Satellite people love performance-enhancing proxies (PEP), add-ons to satellite connections that - generally speaking - get the sending satellite gateway to issue "preemptive" ACKs to the TCP sender. Some PEPs fully break the connection between the two endpoints into multiple connections and even run high-latency variants of TCP across the satellite link itself. However, network people are wary of PEPs as they break the cherished end-to-end principle as well as a number of protocols. There's also very little known about how PEPs scale with large numbers of parallel sessions - in fact, some of the literature suggests that they may not scale well at all. In fact, we have yet to encounter a PEP in the field in the Pacific that will actually reveal itself as such. It's far more common to encounter WAN accelerators - devices built primarily with links between data centres in metropolitan area networks in mind.

Moreover, so far we've only coded individual connections, but they still had to share their journey across the satellite link with conventional TCP under queue oscillation conditions. We don't quite know yet how coding will fare if we coded the traffic for an entire island. We think that the software will scale, and having fewer errors appear at the senders should dampen the queue oscillation, which should in theory allow us to lower the coding overhead. That said, trying this out requires a change in network topology on the island and/or across the satellite link, as the island clients can't be in the same IP subnet as the satellite gateway on the island. This is something we can't try easily on a production system.
So, how about simulation?
When we first went to the islands, we also tried to simulate what was happening on the links using a software network simulator. We knew from our measurements that packet loss was not an issue during off-peak times, so we knew the space segment was working properly in all cases we had looked at. This led us to model the satellite link as a lossless, high latency link with a bandwidth constraint.
Our first stab was to look at simulation in software alone. This confirmed that links with a significant number of longish parallel downloads would oscillate, but it also became apparent pretty quickly that this approach had its limits:
So we resolved that the simulation needed to be done, at least in large parts, in hardware. Having real computers act as clients, servers and peers means we can work mostly with real network componentry. This leaves software to simulate those bits for which hardware is prohibitively expensive - in our case that's of course mainly the satellite link itself.
It so happened that the University of Auckland's satellite TV receiving station was being decomissioned at the time, and we managed to inherit two identical 19" racks, seven feet tall. Once re-homed in our lab, all we had to do was find the hardware to fill them with.
The main challenge in any simulation of this kind of scenario is to simulate the inbound link into the island - it generally carries the bulk of the traffic as servers sit mostly somewhere off-island and clients sit by and large on the island. The standard configuration in the Pacific is to provide capacity on the inbound link that is four times the capacity of the outbound link.
In our case, the clients' main job is to connect to the servers and receive data from the servers. Because our clients don't really have users that want to watch videos or download software, we don't really need them to do much beyond the receiving. They don't even need to store the received data anywhere on disk (so disk I/O is never an issue). All they need to record is how much data they received, and when. This isn't a particularly computing-intensive task, and even small machines such as Raspberry Pis and mini PCs can happily support a significant number of such clients in software. So we were going to fill one of the racks with these sorts of clients. This is the "island" rack.
The other rack is called the "world" rack and houses the simulated satellite link and the "servers of the world". We realised pretty quickly that a clean approach would see us use a dedicated machine for the satellite link itself (I'll drop the word "simulated" from hereon), and one dedicated machine at either end of the link for network coding, PEPing, and measurements. When we don't code or PEP, these machines simply act as plain vanilla routers and forward the traffic to and from the link.
The next question was where we'd get the hardware from. For the world side, Nevil Brownlee already had a small number of Super Micro servers which he was happy to let us use as part of the project. Thanks to a leftover balance in one of Brian Carpenter's research accounts, we were able to buy a few more, plus ten Intel NUCs. Proceeds from a conference bought screens, keyboards, mice, some cables and switches. The end-of-financial-year mop-up 2015 bought us our first dozen Raspberry Pis (model 2B). Peter Abt, a volunteer from Germany, set the NUCs and Pis up.
We also applied to Internet NZ again, whose grant paid for a lot more Pis (the new Model 3B with quad-core processors) and switches and another server, plus a lot of small parts and a few more rack shelves. A departmental capex grant saw us add four more Super Micro servers to the "world" fleet.





The building of the simulator more or less coincided with the electrical safety inspection that the university conducts every few years. The poor sparkies that got tasked with the job expected at best a few cables and power supplies in each room. I'm not sure what they thought when they saw the simulator, but I suspect we had more bits for them to test than some departments. They now greet me whenever they see me on campus.
If we want to do a realistic traffic simulation, we can't just set up a bunch of long FTP downloads. Real-world traffic is a mix of mostly short and very few long TCP flows, with a good dollop of UDP and some ICMP thrown in for good measure. Short TCP flows never live long enough on satellite links to experience the effects of TCP flow control: They often consist of only one or two packets, and by the time the first ACK gets back to the sender, the sender has already sent everything. So if we want to recreate that scenario, we need to gather some intelligence about real traffic first.
One way to do this is to go to a friendly ISP in an island location and collect netflow traces at their border router to the satellite gateway. One caveat here is to ensure that we're responsible citizens: Raw netflow traces are huge files even for just a few minutes worth of traffic. Trying to retrieve them via the satellite link is a surefire way of making yourself unpopular on the island. It's a bit like a surgeon gaining access to your abdomen via keyhole surgery, and then trying to pull your liver out through the hole in one piece. Not smart. So the secret is to keep the traces short and at the very least compress them. Even better: Store the data on a portable drive and physically retrieve it from the island.
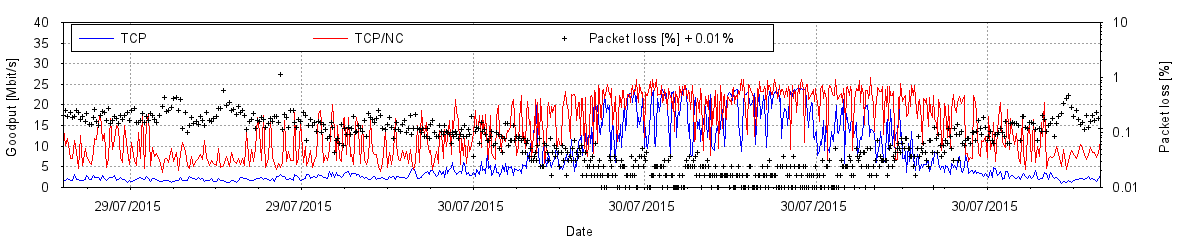
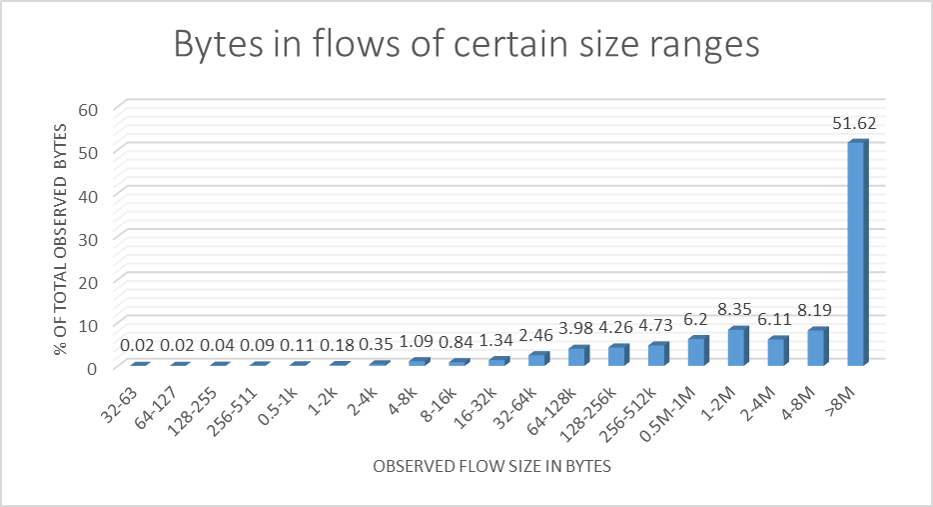
An analysis of netflow traces gives us an idea of how flow sizes are distributed. The two diagrams show an example of what one may observe: Most TCP flows are small, but most of the bytes transferred belong to large flows. So if TCP queue oscillation puts TCP senders of large flows into a start-stop mode of operation but leaves small flows almost unaffected, then it still puts the brakes on the majority of bytes travelling across the link.
So how does one generate a flow mix like this in an environment with multiple clients and servers, while simultaneously ensuring good use of the computational resource? We developed a custom client / server solution, with the client software deployed on the island machines, and the server software on the "world" machines. This is roughly how they work:
Note that this means that each client is engaged in a connection at pretty much any time (except for the short period between being disconnected and attempting the next connection). This lets us control the number of parallel connections rather precisely through the number of physical client machines that we include in an experiment, and the number of instances of the client software that we run on each of these machines.
The satellite link itself is currently being simulated with tc, which lets us control both latency and link bandwidth. The physical separation of the link into its own box should in future also allow us to use more sophisticated link simulator software, such as sns3.
tc also lets us add latency and jitter to the "world" servers, reflecting the fact that in a real satellite network, the latencies between off-island satellite gateway and servers vary considerably. So this lets us have one server for the US West Coast, one for the East Coast, one for Asia, one for Australia, one for NZ, one for the rest of the world - you get the drift.
One challenge that has become apparent is that managing and monitoring experiments on a large number of clients and servers is complex and time-consuming. At present, we have rather rudimentary scripting only, and pulling experimental data off the NUCs and Pis is very much a text file based process. In the year ahead, we'll need to develop tools to help us configure and read the system more efficiently - there has to be a better way that's less prone to finger trouble!
Any complex system has its perils, so the first phase of experimentation with the simulator has been to ensure that the components play well together. So we've run a number of experiments to verify that everything works as it should. These have included, among others:
Now that we've implemented the base version of the simulator, we're ready to do our first actual simulations. On our to-do list:
To get through this list, we'll need to develop the simulator further. We'll probably need more hardware, but we'll also need to develop a significant number of tools to assist us in the experiments. These include command and control tools that let us distribute our software and configuration updates quickly to the machines, configure and run experiments easily involving the large number of machines, and tools that will let us retrieve experimental data from the NUCs, Pis, and other machines reliably after experiments, process that data, and store it for further use. Note that each machine needs to concentrate on actually running experiment while they're on; it wouldn't be a good idea to use the same network to send the resulting trace information to a central collection point at the same time.
We'll also need to look closely at issues such as how we'll simulate UDP flows. At present, we can analyse the flow data from the islands, but this only tells us how much UDP arrived, not how much was sent in order to achieve that quantity on the island side. UDP traffic always pre-loads the link to a certain extent, but as it's also affected by queue drops, TCP can "squeeze" it a little, too. Having a simulator here means that we'll be able to cheat, though, to a certain extent, as we don't have to take feedback latency into consideration for UDP. Last but not least, simulating different networks on the "world" side is an ideal application for software-defined networking (SDN), too.
August 30, 2016: ISIF Asia have just announced that the new development work above will be supported by an APNIC Internet Operations Research Grant of AUD 45,000. We were one of 10 projects chosen from over 300 applications. Very happy of course!
August 2016: How many concurrent TCP client or server sockets can you support sustainably with a Debian or Ubuntu machine if you're wanting all connections to run full bore but share the network capacity fairly? In our simulator, that's just what we'd like to do, of course. Answer: Less than you may think. Our experiments with different clients and servers show that the number is around 20-25. Tweaking parameters doesn't seem to help much. Yes you can run more sockets, but they'll show little to now activity in terms of data transfer. This puzzled us a little but the root of the problem isn't a network or network stack problem. Rather, it seems to lie in the order in which POSIX-compliant OS assign file descriptors (file handles), and in which order the OS then performs operations on them when it then gets around to the job. The file dsscriptors are also used for socket I/O. It's all a little complex, but we now have relatively simple toy model for what's happening and are actually able to simulate the issue with it. I've just spent a couple of weeks working with Aaron Gulliver of the University of Victoria (Canada) on it - the toy model itself is a very interesting theoretical problem!