



Next: Delta Rule vs. Perceptron
Up: Neural Network Learning
Previous: Stochastic Gradient Descent
- In GD the error is summed over all examples before updating
weights, in SGD weights are updated upon examining each training
example
- Summing over multiple examples in GD requires more computation
per weight update step. But since it uses the True gradient, it is
often used with a larger step size
- If there are multiple local minima with respect to
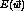 , SGD can sometimes avoid falling into these local
minima
, SGD can sometimes avoid falling into these local
minima
Patricia Riddle
Fri May 15 13:00:36 NZST 1998