



Next: Differences between GD and
Up: Neural Network Learning
Previous: Problems with Gradient Descent
- Approximate gradient descent search by updating weights
incrementally, following the calculation of the error for each
individual example
- delta rule:
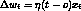 (same as
LMS algo, but only similar to perceptron training rule)
(same as
LMS algo, but only similar to perceptron training rule) - error function:
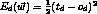
- If
 is sufficiently small, stochastic gradient descent
(SGD)
can be made to approximate true gradient descent (GD) arbitrarily closely
is sufficiently small, stochastic gradient descent
(SGD)
can be made to approximate true gradient descent (GD) arbitrarily closely
Patricia Riddle
Fri May 15 13:00:36 NZST 1998