Major goals of texture research in computer vision are to understand, model and process texture, and ultimately to simulate human visual learning process using computer technologies.
A typical computer vision system can be divided into components such as the ones show in Fig 4.7. Texture analysis might be applied to various stages of the process. At the preprocessing stage, images could be segmented into contiguous regions based on texture properties of each region; At the feature extraction and the classification stages, texture features could provide cues for classifying patterns or identifying objects.
As a fundamental basis for all other texture-related applications, texture analysis seeks to derive a general, efficient and compact quantitative description of textures so that various mathematical operations can be used to alter, compare and transform textures. Most available texture analysis algorithms involve extracting texture features and deriving an image coding scheme for presenting selected features. These algorithms might differ in either which texture features are extracted or how they are presented in the description. For example, a statistical approach describes a texture via image signal statistics which reflect nondeterministic properties of spatial distribution of image signals. A spectral method extracts texture features from the spectral domain . A structural approach considers a texture as a hierarchy of spatial arrangements of well-defined texture primitives. A probability model describes the underlying stochastic process that generates textures. Several representative works on texture analysis will be reviewed in more detail in Chapter 5.
Four major application domains related to texture analysis are texture classification, texture segmentation, shape from texture, and texture synthesis [98]. Below, each domain is described briefly.
Texture classification assigns a given texture to some texture classes [14,30,75,79,93,63,100,101]. Two main classification methods are supervised and unsupervised classification. Supervised classification is provided examples of each texture class as a training set. A supervised classifier is trained using the set to learn a characterisation for each texture class. Unsupervised classification does not require prior knowledge, which is able to automatically discover different classes from input textures. Another class is semi-supervised with only partial prior knowledge being available.
The majority of classification methods involve a two-stage process. The first stage is feature extraction, which yields a characterisation of each texture class in terms of feature measures. It is important to identify and select distinguishing features that are invariant to irrelevant transformation of the image, such as translation, rotation, and scaling. Ideally, the quantitative measures of selected features should be very close for similar textures. However, it is a difficult problem to design a universally applicable feature extractor, and most present ones are problem dependent and require more or less domain knowledge.
The second stage is classification, in which classifiers are trained to determine the classification for each input texture based on obtained measures of selected features. In this case, a classifier is a function which takes the selected features as inputs and texture classes as outputs.
In the case of supervised classification, a ![]() -nearest
neighbour (
-nearest
neighbour (![]() -NN) classifier is usually
applied [79,101], which determines the classification
of a texture by computing distances to the
-NN) classifier is usually
applied [79,101], which determines the classification
of a texture by computing distances to the ![]() nearest training
cases. The distances are computed in a multi-dimensional
feature space constructed by selected texture features.
Euclidean distance, Chi-square distance, and Kullback-Leibler
distance [58] are mostly used as distance metrics for
distributions and thus similarity metrics for textures. A Bayesian
classifier that performs classification via probabilistic inference
is also frequently used. A general two-class Bayesian classifier can
be specified by the following Bayes formula [27],
nearest training
cases. The distances are computed in a multi-dimensional
feature space constructed by selected texture features.
Euclidean distance, Chi-square distance, and Kullback-Leibler
distance [58] are mostly used as distance metrics for
distributions and thus similarity metrics for textures. A Bayesian
classifier that performs classification via probabilistic inference
is also frequently used. A general two-class Bayesian classifier can
be specified by the following Bayes formula [27],
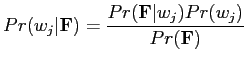
Leung and Malik [63] developed a state-of-the-art
feature-based method for classifying 3D textures under varying
viewpoint and illumination. In feature extraction, the method
applies a filter bank onto the training textures for each material
with known viewpoints and illumination. A k-mean clustering
algorithm is exploited to identify k clusters from the vector
space concatenating all filter responses. Cluster centres are the
representative textons of each material and act as feature
descriptors. The textons of all materials together create a global
texton dictionary, so that each material is represented by a
particular probability density function,i.e. the distribution of
texton frequencies, with respect to the dictionary. For a novel
texture to be classified, the distribution of texton frequencies
with respect to the texton dictionary is computed, for a ![]() classifier to assign the texture to a class with the nearest
distribution of texton frequencies. Figure 4.3.1
shows examples of textures and their corresponding texton
distribution with respect to a texton dictionary [101].
classifier to assign the texture to a class with the nearest
distribution of texton frequencies. Figure 4.3.1
shows examples of textures and their corresponding texton
distribution with respect to a texton dictionary [101].
Texture classification can sort image data into more readily interpretable information, which is used in a wide range of applications such as industrial inspection, image retrieval [91], medical imaging and remote sensing [90].
|
Texture segmentation [23,24,51,73,75,47,71,56] partitions an image into a set of disjoint regions based on texture properties, so that each region is homogeneous with respect to certain texture characteristics. Results of segmentation can be applied to further image processing and analysis, for instance, to object recognition. Similar to classification, segmentation of texture also involves extracting features and deriving metrics to segregate textures. However, segmentation is generally more difficult than classification, since boundaries that separate different texture regions have to be detected in addition to recognising texture in each region.
Texture segmentation could also be supervised or unsupervised depending on if prior knowledge about the image or texture class is available. Supervised texture segmentation identifies and separates one or more regions that match texture properties shown in the training textures. Unsupervised segmentation [47,73] has to first recover different texture classes from an image before separating them into regions. Compared to the supervised case, the unsupervised segmentation is more flexible for real world applications despite that it is generally more computationally expensive.
Partitioning an image into homogeneous regions is very useful in a variety of applications of pattern recognition and machine leaning. For example, in remote sensing and GIS analysis, texture segmentation could be applied to detect landscape change from an aerial photo. Figure 4.9 illustrates such an application of texture segmentation which finds different ground objects, such as rural, industrial residential areas, based on their distinct texture properties appeared in the image [106].
Shape from texture is the problem of estimating a 3D surface shape by analysing texture property of a 2D image. Weak homogeneity or isotropy of a texture is likely to provide a shape cue [17]. For instance, texture gradient is usually resulted from perspective projection when the surface is viewed from a slant, which infers the parameters of surface shape or the underlying perspective transformation. Therefore, via a proper measure of texture gradient, a depth map and the object shape could be recovered.
Shape from texture have been used for recovering true surface orientation, reconstructing surface shape, and inferring the 3D layout of objects, in many applications [50,61,31]. For example, the plane vanish line could be computed from texture deformation in an image [19], which could be used to affine rectify the image.
In computer graphics, texture synthesis is a common technique to create large textures from usually small texture samples, for the use of texture mapping in surface or scene rendering applications. A synthetic texture should differ from the samples, but should have perceptually identical texture characteristics [22]. The main advantage of texture synthesis in this case is that it can naturally handle boundary condition and avoid verbatim repetitions. In computer vision, texture synthesis is of interest also because it provides an empirical way to test texture analysis. Because a synthesis algorithm is usually based on texture analysis, the result justifies effectiveness of the underlying models. Compared to texture classification and segmentation, texture synthesis poses a bigger challenge on texture analysis because it requires a more detailed texture description and also reproducing textures is generally more difficult than discriminating them.
Other applications of texture synthesis include image editing [9], image completion [26], and video synthesis [59], etc.
|
![\includegraphics[height=4in]{visionsystem.eps}](img10.png)
![\includegraphics[scale=0.6]{texton_pdf.eps}](img20.png)
![\includegraphics[scale=0.3]{TS-orig.bmp.eps}](img21.png)
![\includegraphics[scale=0.3]{TS-1.bmp.eps}](img22.png)
![\includegraphics[scale=0.3]{TS-2.bmp.eps}](img23.png)
![\includegraphics[scale=0.3]{TS-3.bmp.eps}](img24.png)
![\includegraphics[scale=0.7]{windows.eps}](img25.png)
![\includegraphics[scale=0.7]{windows_g2.eps}](img26.png)