![[Return to Library]](BOOKSHLF.GIF)
![[TOC]](TOC.GIF)
![[PREV]](REW.GIF)
![[NEXT]](FF.GIF)
![[INDEX]](INDEX.GIF)
![[Help]](HELP.GIF)
To ensure that you can analyze crash dump files following a system crash, you must understand how crash dump files are created. You must reserve space on disks for the crash dump and crash dump files. The amount of space you reserve depends on your system configuration and the type of crash dump you want the system to perform.
This chapter gives the following information to help you manage crash dumps and crash dump files:
For information about analyzing the contents of crash dump files, see Chapter 5.
Before the system writes a crash dump, it determines how the dump fits
into the swap partitions. The following list describes how the system determines
where to write the crash dump:
Each crash dump contains a header, which the
system always writes to the end of the primary swap partition. The header
contains information about the size of the dump and where the dump is stored.
This information allows the system to find and save the dump at system reboot
time.
You can configure the system
so that it fills the secondary swap partitions with dump information before
writing any information (except the dump header) to the primary swap partition.
The attribute that you use to configure where crash dumps are written first
is the dump_sp_threshold attribute.
The value in the dump_sp_threshold attribute indicates the
amount of space you normally want available for swapping as the system reboots.
By default, this attribute is set to 4096 blocks, meaning that the system
attempts to leave 2 MB of disk space open in the primary swap partition after
the dump is written.
Figure 4-1 shows the default setting of the dump_sp_threshold attribute for a 40 MB swap partition.
The system can write 38 MB of dump information to the primary swap partion
shown in Figure 4-1. Therefore, a 30 MB dump fits on the
primary swap partition and is written to that partition. However, a 40 MB
dump is too large; the system writes the crash dump header to the end of the
primary swap partition and writes the rest of the crash dump to secondary
swap partitions.
Setting the dump_sp_threshold attribute to a high value causes
the system to fill the secondary swap partitions before it writes dump information
to the primary swap partion. For example, if you set the dump_sp_threshold attribute to a value that is equal to the size of the primary swap
partition, the system fills the secondary swap partitions first. (Setting
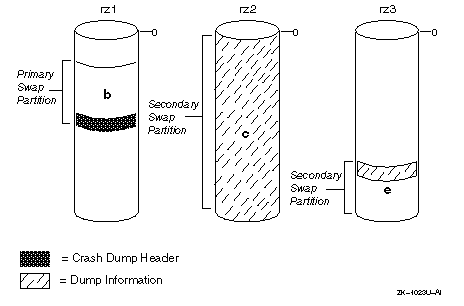
the dump_sp_threshold attribute is described in Section 4.3.3.) Figure 4-2 illustrates how a crash dump is written to secondary
swap partitions on multiple devices.
If the crash dump fills partition e in Figure 4-2,
the system writes the remaining crash dump information to the end of the primary
swap partition. Note that the system fills as much of the primary swap partition
as is necessary to store the entire dump. The dump is written to the end
of the primary swap partition to attempt to protect it from system swapping.
However, the dump can fill the entire primary swap partition and might be
corrupted by swapping that occurs as the system reboots.
A partial crash dump contains the following:
The system writes the part of physical memory believed to contain significant
information at the time of the system crash. By default, the system omits
user page table entries.
A full crash dump contains the following:
If you want the system to
include user page tables in partial crash dumps, set the value of the dump-user-pte-pages attribute to 1. The dump-user-pte-pages
attribute is in the vm subsystem. The following example shows the
command you issue to set this attribute:
The sysconfig command changes the value of system attributes
for the currently running kernel. To store the new value of the dump-user-pte-pages attribute in the sysconfigtab database, modify that database
using the sysconfigdb command. For information about the sysconfigtab database and the sysconfigdb command, see the System Administration
manual and the
To return to the system default of not writing user page tables to partial
crash dumps, set the value of the dump-user-pte-pages attribute
to 0 (zero).
To set this console
environment variable, shut down and halt your system. At the console prompt,
enter the following command:
Because crash dumps are written to the swap partitions on your system,
you allow space for crash dumps by adjusting the size of your swap partitions.
For information about modifying the size of swap partitions, see the System Administration
manual and the Installation Guide.
The sections that follow give guidelines for estimating the amount of
space required for partial and full crash dumps. In addition, setting the dump_sp_threshold attribute is described.
If your swap partitions are too small to store a partial crash dump,
the system creates no crash dump. Therefore, overestimate the amount of space
you need and adjust the amount of space you allocate to saving crash dumps,
if necessary, after your system creates a few crash dumps.
Because crash dumps are about the same size as crash dump files, you
can determine how large a crash dump was by examining the size of the resulting
crash dump file. For example, to determine how large the first crash dump
file created by your system is, issue the following command:
This command displays the number of 512-byte blocks occupied by the
crash dump file. In this case, the file occupies 20,480 blocks, so you know
that the crash dump written to the swap partitions also occupied about 20,480
blocks. Be sure to use the ls -s command to display the size of
crash dump files. The size that the ls -l command displays is incorrect.
The ls -l command includes file "holes" in the size
of the crash dump file. (See Section 4.6 for more information.)
In some cases, a system contains so much active memory that it cannot
store a crash dump on a single disk. For example, suppose your system contains
2 GB of memory and system activity level is high (uses most of memory). Crash
dumps for this system are too large to fit on a single device. To cause crash
dumps to spread across multiple disks, set the dump_sp_threshold
attribute to a high value, as described in Section 4.3.3,
and create secondary swap partitions on several disks. The system automatically
writes dumps that are too large to fit in the primary swap partition to secondary
swap partitions. The System Administration manual describes configuring swap space.
If your system contains a large amount (2 GB, for example) of memory,
it might need to spread crash dumps across multiple disks. To cause crash
dumps to spread across multiple disks, set the dump_sp_threshold
attribute to a high value, as described in Section 4.3.3,
and create secondary swap partitions on several disks. The system automatically
writes dumps that are too large to fit in the primary swap partition to secondary
swap partitions. The System Administration manual describes configuring swap space.
If you chose to have the system perform a full dump when it crashes
and your swap partitions are too small to store a full dump, the system performs
a partial dump.
To adjust the dump_sp_threshold attribute, issue the sysconfig command. For example, suppose your primary swap partition
is 40 MB. To raise the value so that the system writes crash dumps to secondary
partitions, issue the
following command:
The sysconfig command changes the value of system attributes
for the currently running kernel. To store the new value of the dump_sp_threshold attribute in the sysconfigtab database, modify that database
using the sysconfigdb command. For information about the sysconfigtab database and the sysconfigdb command, see the System Administration
manual and the
You can invoke the savecore command from the command line.
For information about the command syntax, see the
If a crash dump
exists and the file system contains enough space to save the crash dump files,
the savecore command moves the crash dump and a copy of the kernel
into files in the default crash directory, /var/adm/crash. (You
can modify the location of the crash directory, as described in Section 4.5.)
The savecore command stores the kernel image in a file named vmunix.n, and it stores the contents of physical memory in
a file named vmcore.n.
The n
variable specifies the number of the crash. The number of the crash is recorded
in the bounds file in the crash directory. After the first crash,
the savecore command creates the bounds file and stores
the number 1 in it. The command increments that value for each succeeding
crash.
The savecore command runs early in the reboot process so
that little or no system swapping occurs before the command runs. This practice
helps ensure that crash dumps are not corrupted by swapping.
The savecore command saves the
binary event buffer in the /usr/adm/crash/binlogdumpfile file by
default. You can change the location to which savecore writes the
binary event buffer by modifying the dumpfile entry in the /etc/binlog.conf file. If you remove the dumpfile entry from
the /etc/binlog.conf file, savecore does not save the
binary event buffer.
Later in the reboot process the binlogd daemon starts up, reads the contents of the /usr/adm/crash/binlogdumpfile file, and moves those contents into the /usr/adm/binary.errlog file, as specified in the /etc/binlog.conf file. The binlogd daemon then deletes the binlogdumpfile file. For
more information about how binary error logging is performed, see the System Administration
manual and the
For example, suppose you save partial crash dumps. Your system has
96 MB of memory, but your peak system activity level is 80 MB. You have reserved
85 MB of disk space for crash dumps and swapping. In this case,
you should reserve 91 MB of space in the file system for storing crash dump
files. You need to reserve considerably more space if you want to save files
from more than one crash dump. If you want to save files from multiple crash
dumps, consider compressing older crash dump files. See Section 4.6
for information about compressing and uncompressing partial crash dump files.
By default, savecore writes crash dump files to the /var/adm/crash directory.
To reserve space for crash dump files in the default directory, you must
mount the /var/adm/crash directory on a file system that has a
sufficient amount of disk space. (For information about mounting file systems,
see the System Administration manual and the
If your system cannot save crash dump files due to insufficient disk
space, the system returns to single-user mode. This return to single-user
mode prevents system swapping from corrupting the crash dump. Once in single-user
mode, you can make space available in the crash directory or change the crash
directory. One possibility in this situation is to issue the savecore command at the single-user mode prompt. On the command line, specify
the name of a directory that contains a sufficient amount of file space to
save the crash dump files. For example, the following savecore
command writes crash dump files to the /usr/adm/crash2 directory:
Specifying a directory on the savecore command line changes
the crash directory only for the duration of that command. If the system crashes
later and the system startup script invokes the savecore script, savecore copies the crash dump to files in the default directory, which
is normally /var/adm/crash.
You can
control the default location of the crash directory with the rcmgr
command.
For example, to save crash
dump files in the /usr/adm/crash2 directory by default (at each
system startup), issue the following command:
If you want the system
to return to multiuser mode, regardless of whether it saved a crash dump,
issue the following command:
If you compress a vmcore.n dump file from a
partial crash dump, you must use care when you uncompress it. Using the uncompress command with no flags results in a vmcore.n
file requiring space equal to the size of memory. In other words, the uncompressed
file requires the same amount of disk space as a vmcore.n
file from a full crash dump.
This situation occurs because the original vmcore.n
file contains UNIX File System (UFS) file "holes." UFS files
can contain regions, called holes, that have no associated data blocks. When
a process, such as the uncompress command, reads from a hole in
a file, the file system returns zero-valued data. Thus, memory omitted from
the partial dump is added back into the uncompressed vmcore.n file as disk blocks containing all zeros.
To ensure that the uncompressed core file remains at its partial dump
size, you must pipe the output from the uncompress command with
the -c flag to the dd command with the conv=sparse option. For example, to uncompress a file named vmcore.0.Z,
issue the following command:
Some systems have no Halt button. In this case, follow these steps
to force a crash dump on a hung system:
If your system hangs and
you force a crash dump, the panic string recorded in the crash dump is the
following:
![]()
4.1 Crash Dump Creation
When the system creates a crash
dump, it writes the dump to the swap partitions. The system uses the swap
partitions because the information stored in those partitions has meaning
only for a running system. Once the system crashes, the information is useless
and can be safely overwritten.Note
Figure 4-1: Default dump_sp_threshold Attribute Setting
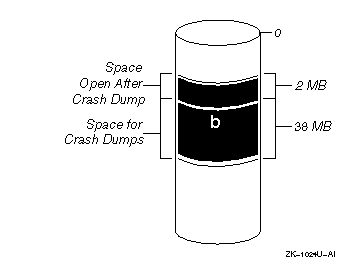
Figure 4-2: Crash Dump Written to Multiple Devices

4.2 Choosing the Contents of Crash Dumps
Crash dumps are partial (the
default) or full. Normally, partial crash dumps provide the information that
you need to determine the cause of a crash. However, you might want the system
to generate full crash dumps if you have a recurring crash problem and partial
crash dumps have not been helpful in finding the cause of the crash.
As explained in the sections that follow, you can control
the contents of crash dumps in the following two ways:
4.2.1 Including User Page Tables in Partial Crash Dumps
By
default, the system omits user page tables from partial crash dumps. These
tables do not normally help you determine the cause of a crash and omitting
them reduces the size of crash dumps and crash dump files.
# sysconfig -r vm dump-user-pte-pages = 1
sysconfigdb(8) reference page.
4.2.2 Selecting Partial or Full Crash Dumps
By default, the
system generates partial crash dumps. If you want the system to generate full
crash dumps, you can modify the default behavior in the following ways:
To return to partial crash dumps, remove the d
flag from the boot_osflags environment variable or set the partial_dump variable to 1.
>>> set boot_osflags d
The boot_osflags variable controls other boot options, such as whether the system boots
to single-user mode or multiuser mode; therefore, use care when setting this
variable. For more information about boot_osflags, see the System Administration
manual.
(dbx) a partial_dump = 0
4.3 Planning Crash Dump Space
Note
4.3.1 Estimating the Size of Partial Crash Dumps
Normally,
a partial crash dump contains only a part of physical memory, so you allocate
less disk space to saving a partial crash dump than you allocate for a full
crash dump. The amount of space required to save a partial crash dump varies,
depending on the level of system activity. For example, suppose your system
has 128 MB of memory, but your peak system activity level is low (never uses
more than 60 MB of memory.) In this case, you might allow 70 MB of disk space
for storing crash dumps.
# ls -s /var/adm/crash/vmcore.0
20480 vmcore.0
4.3.2 Estimating the Size of Full Crash Dumps
Full crash
dumps provide you the maximum information about the system at the time of
the crash. However, this type of crash dump occupies a large amount of disk
space. If you intend to save full crash dumps, you need to create swap partitions
equal to the size of memory, plus 1 additional block for the crash dump header.
For example, if your system has 128 MB of memory, your swap partitions must
provide at least 129 MB of disk space, with at least 1 block of disk space
in the primary swap partition to store the crash dump header.
4.3.3 Adjusting the Primary Swap Partition's Crash Dump Threshold
To configure your system so that it writes crash dumps to secondary
swap partitions before the primary swap partition, use the dump_sp_threshold attribute. As described in Section 4.1,
the value you assign to this attribute indicates the amount of space that
you normally want available for system swapping after a system crash.
# sysconfig -r generic dump_sp_threshold=20480
In the preceding example, the dump_sp_threshold
attribute, which is in the generic subsystem, is set to 20,480
512-byte blocks (40 MB). In this example, the system attempts to leave the
entire primary swap partition open for system swapping. The system automatically
writes the crash dump to secondary swap partitions and the crash dump header
to the end of the primary swap partition.sysconfigdb(8) reference page.
4.4 Crash Dump File Creation and Crash Dump Logging
After a system crash, you normally
reboot your system by issuing the boot command at the console prompt.
During a system reboot, the /sbin/init.d/savecore script invokes
the savecore command. This command moves crash dump information
from the swap partitions into a file and copies the kernel that was running
at the time of the crash into another file. You can analyze these files to
help you determine the cause of a crash. The savecore command
also logs the crash in system log files.savecore(8) reference
page.
4.4.1 Crash Dump File Creation
When the savecore command begins running during the reboot process, it determines
whether a crash dump occurred and whether the file system contains enough
space to save it. (The system saves no crash dump if you shut it down and
reboot it; that is, the system saves a crash dump only when it crashes.)
4.4.2 Crash Dump Logging
Once the savecore command writes the crash dump files, it performs the following steps
to log the crash in system log files:
binlogd(8) reference page.
4.5 Planning and Allocating File System Space for Crash Dump Files
The size of crash
dump files varies, depending on whether you use partial crash dumps or full
crash dumps. In the case of partial crash dumps, the size of the files also
depends on the level of system activity at the time of the crash. A general
guideline is to reserve, at a minimum, the amount of space you estimate you
need to save crash dumps, plus 6 MB. The vmunix.n
file occupies about 6 MB of disk space. You can adjust this amount if need
be once your system has attempted to save several crash dump files.mount(8) reference page.) If
you expect your crash dump files to be large, you might need to use a Logical
Storage Manager (LSM) file system to store crash dump files. For information
about creating LSM file systems, see the Logical Storage Manager manual.
# savecore /usr/adm/crash2
Once savecore has saved the crash dump files, you can bring your system to
multiuser mode.
# /usr/sbin/rcmgr set SAVECORE_DIR /usr/adm/crash2
# /usr/sbin/rcmgr set SAVECORE_FLAGS M
4.6 Compressing and Uncompressing Crash Dump Files
If
you want to store files from more than one crash, you might find it useful
to compress the crash dump files. In particular, you should compress the
vmcore.n files.
# uncompress -c vmcore.0.Z | dd of=vmcore.0 conv=sparse
262144+0 records in
262144+0 records out
4.7 Creating Dumps of a Hung System
You can force
the system to create a crash dump when the system hangs. On most hardware
platforms, you force a crash dump by following these steps:
hardware restart
This panic
string is always the one recorded when system operation is interrupted by
pressing the Halt button or Ctrl/P.