



Next: Q Learning Properties
Up: Reinforcement Learning
Previous: Finding Optimal Policies
- optimal action is the one that maximizes the sum
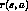 and
and
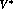 to the immediate successor state discounted by
to the immediate successor state discounted by 
-
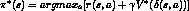
- but must have perfect knowledge of reward function
 and the
state transition function
and the
state transition function  !!!
!!! - so create the Q function,
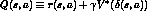
- now
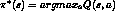
- now we can select optimal actions even when we have no
knowledge of or
- Q value for each state-action transition equals the value
for this transition plus the value for the resulting state
discounted by
Patricia Riddle
Fri May 15 13:00:36 NZST 1998