A metric that gets measured a lot (although it's not clear how much it is used) is what I will call Number of Linearly Independent Paths (NLIP). This is more commonly known as McCabe's Cyclomatic Complexity Number (CCN) [McC76], but I don't like that name because, not only does it not actually measure "complexity", but it also obscures what it actually does measure, making it not always obvious how to apply it in new situations. By using a new name, I am in particular indicating that however people may have defined CCN in the past, by using NLIP I mean what I define here.
The situations I have in mind are the ternary operator ?:, the switch statement, and exceptions. While these aren't exactly "new", they also don't seem to be discussed so it's not immediately clear how to deal with them. In the following I will try to do so.
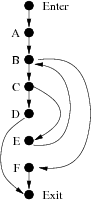
First I need to be clear on what it is that's being measured. For a useful piece of code (in this case, I'm talking about the bodies of methods), we can represent the control flow in it with a flowgraph [FP96]. This is a graph where the vertices are statements and the edges indicate possible control flow between statements. Consider the following example:
public static boolean isPrime(int n) {
A int i = 2;
B while (i < n) {
C if (n % i == 0) {
D return false
}
E i++;
}
F return true;
}
|
The flowgraph for this example below. Note that I've added nodes representing the entry and exit to the method. This, in particular, makes it easier to represent multiple exit points, such as the example has (two return statements).
A path through a flowgraph starts at the Enter vertex
and follows edges until the Exit vertex is reached. A set of
paths are linearly independent if there none of them can be created
by combining the others in some way. It may take a bit of staring, but in
the case of our example above, there are at most three such paths, as shown
here:
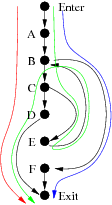
Proving that this flowgraph has at most three linearly independent paths involves converting the graph into a vector space and applying some linear algebra, which I won't do here. However, graph theory tells us that for graphs with the properties that flowgraphs have, the maximum number of linearly independent paths is e - n + 2, where e is the number of edges and n is the number of vertices. In the case of the example, n = 8, e = 9, so NLIP = 9 - 8 + 2 = 3.
Creating a flowgraph can get a bit tedious, but fortunately graph theory again comes to our rescue and tells us that for flowgraphs the maximum number of linearly independent paths is d + 1, where d is the number of decision vertices. A decision vertex corresponds to a conditional branch in the code. Decision vertices are easy to spot — they are the ones that have multiple edges leaving them, or with out-degree greater than 1. In fact, that this property almost certainly requires that such vertices have out-degree exactly 2, which is certainly true of the standard conditional statements such as if or while. (But more on this in a moment.)
Returning to our example, we see two decision vertices, and they correspond to the while and if statements. So again we get 3 linearly independent paths.
Once we cast linearly independent paths in terms of conditional branches, it becomes a little easier to see why d + 1 works. In the case of the example, the while condition will be either true or false, so we get at least two paths there. The true case will take us eventually to the if condition, which again leads to two paths coming out. So for the paths given in the figure, the red path corresponds to the while condition being true followed by the if condition being true; the green path corresponds to the while condition being true followed by the if condition being false; and the blue path corresponds to the while condition being false. Since there are no other possible combinations of conditions, we can't have more than 3 paths.
Ok, so why might we care about linearly independent paths? The main reason (and in fact the one put forward by McCabe) is that it gives us some idea about how much testing is going to be needed. As each path corresponds to a different combination of results of the conditions, it is reasonable that we should make sure we have at least one test case for each path. In some sense, the NLIP for a method is the minimum number of test cases needed to adequately test the method. In reality, the minimum number of test cases is almost certainly much larger than NLIP, but it's a good start.
So what about the three situations I mentioned at the beginning? First,
the ternary operator ?:. This has been raised as a potential
issue when measuring according to a metric such as NLIP. If we
think of it in testing terms, then an argument is that we should have tests
for both cases of the condition, since different code could be executed
depending on the condition. However since flowgraphs are usually expressed
with vertices being statements, not expressions, this interpretation of
ternary operators seems questionable, so I don't consider the ternary
operators as a decision vertex.
It's interesting to note that McCabe considered the case of compound predicates, e.g., cond1 && cond2 and seemed to suggest that the two conditions of the predicate be considered separately. However he didn't really expand upon this suggestion, and it is also inconsistent with the definition of flowgraphs he gives. Note that this treatment of predicates is now referred to as condition coverage.
Switch statements are a little less obvious. They are kind of like multi-way conditions, that is, would normally correspond to vertices with an out-degree greater than 2, and so the normal measurement rules would appear not to apply. The way around this is to realise that switch statements can be rewritten using if statements. This makes the condition structure (particularly in terms of testing requirements) much clearer. Specifically, switch statement can be re-written as if statements with as many conditions as there are labels (default does not count as a label). Use of "fall-throughs" might appear to make things more tricky, but it works out the same (albeit with some duplication of code). An example of the transformation is as follows. Starting with:
switch (a) {
case one: // do case one
break;
case two: // do case two, this with fall through
case three: // do case three
break;
case four: // do case four
default: // default case
}
|
if (a == one) {
// do case one
} else if (a == two) {
// do case two
// do case three
} else if (a == three) {
// do case three
} else if (a == four) {
// do case four
} else {
// default
}
|
We started with four labels and ended up with four conditionals. While this is not a proof, hopefully this is convincing enough. Those who require a proof are welcome to supply one. (Interestingly, while switch or cases statements often aren't mentioned when discussing CCN, McCabe did discuss them. I suspect he was referring to a case statement with different behaviour than the Java switch statement, as he gets a slightly different answer to me.)
The last situation of concern is that of exceptions, and is much more complicated. Consider the following example:
public void aMethod(Object obj) {
// some code without conditionals
obj.toString();
// more code without conditionals
}
|
The normal rules would say that this example has NLIP of 1
(there being no conditionals), corresponding to the single path through the
code. However, the dereference of obj gives the possibility of
a NullPointerException being thrown. This adds another possible
path that gets to the dereference and then exits the method. Since any
dereference has the possibility of throwing a NullPointerException,
in the worst case there are at least as many paths as there are
dereferences. Add other kinds of exceptions that can be thrown, and we get
even more paths, and the new ones require non-trivial analysis to determine
(namely figuring out which statements can cause which exceptions to be
thrown). If we consider all of these different paths as part of
the NLIP definition, then the resulting measurements will be values
that completely overwhelm the number of linearly independent paths we
actually care about. For this reason, I do not consider the possibility of
uncaught exceptions being thrown as contributing to NLIP.
Now let's consider try statements, as in the following example:
...
try {
// some code
FileInputStream f = new FileInputStream("foo");
// more code
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (SecurityException e2) {
e2.printStackTrace();
} finally {
System.out.println("finally!");
}
...
|
Again the throwing of an exception (in the call to the FileInputStream constructor) adds new paths, but this time they are to a catch clause, not the method exit. Again, this possibility exists for any statement that can throw a FileNotFoundException in the try clause, and multiple catch clauses complicate the situation. There is a difference in this case to the previous example however — in this case there is other code (that in a catch clause) that is executed as a result of an exception being thrown. If we recall our motivation for considering linearly-independent paths, namely constructing test cases, then we definitely want a test case that causes the code in the catch clause to execute. So in this case, each catch clause is considered a conditional when it comes to computing NLIP. Note that the presence of the finally clause has no impact on the value of NLIP, as it is always executed.
| Language construct | Decision points | Notes |
|---|---|---|
| if statement | 1 | |
| while statement | 1 | |
| do statement | 1 | |
| for statement | 1 | Both forms |
| ?: statement | 1 | |
| catch clause | 1 | 1 per clause |
| case label | 1 | 1 per label |
| default label | 1 |