Research Paper Review
COMPSCI 765 S2 C Advanced Artificial Intelligence 2005
Reviewer
Daniel Flower (dflo006@ec.auckland.ac.nz)
Reference
Anthony K. H. Tung; Jean Hou; Jiawei Han (2001). Spatial Clustering in the Presence of Obstacles,
Proceedings of the 17th International Conference on Data Engineering, Pages: 359 - 367, ISBN:0-7695-1001-9
Online: click here
Keywords
Spatial clustering, spatial data mining, cluster analysis, clustering with obstacles
Related Papers
R. Ng and J. Han, (1994) Efficient and effective clustering method for spatial data mining, In Proc. 1994
Int. Conf. Very Large Data Bases, pages 144-155, Santiago, Chile, Sept. 1994.
M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, (1996) A density-based algorithm for discovering clusters in
large spatial databases, In Proc. 1996 Int. Conf. Knowledge Discovery and Data Mining, pages 226-231, Portland, Oregon, Aug. 1996.
M. Ankerst, M. Breunig, H.-P. Kriegel, and
J. Sander, (1999) OPTICS: Ordering points to identify the clustering structure, In Proc. 1999 ACMSIGMOD
Int. Conf. Management of Data, pages 49-60, Philadelphia, PA, June 1999.
A. Hinneburg and D. A. Keim, (1998) An efficient approach to clustering in large multimedia databases
with noise, In Proc. 1998 Int. Conf. Knowledge Discovery and Data Mining, pages 58-65, New York, NY, Aug. 1998.
Summary
This paper deals with spatial clustering where obstacles are present in the environment. "Clustering" is a term taken from data mining, which is the process of grouping together similar data points in order to find trends in the data or correlations. For example, in a supermarket cluster analysis may find that the sale of wine clusters around the time period of Friday evenings, and so it may be decided to promote the wine more on Friday evenings.
Spatial clustering is simply the application of clustering based on the positions of objects in space. For example, on a map that contained the locations of residential households, clustering analysis could identify the main groups of residential areas which would be useful for determining the number and placement of schools in the area, etc.
This paper is concerned with a specific type of spatial clustering. Given a set of points in space, the goal is to group the points into k discrete groups, where k is a predefined number, with the goal that the average distance of each point to the centre of its group is minimised. The example they give involves the placement of ATMs in a town. A bank can only afford to place four ATMs in a town, and they wish to ensure that the distance from each customer's home to an ATM is minimised. A map showing the layout of the town and the location of each customer's home is supplied (each black dot is one customer's home):
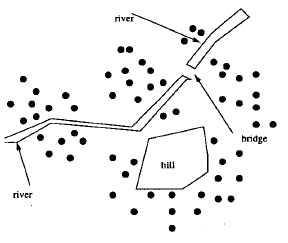
The authors state that conventional spatial clustering algorithms, which normally measure distance using the direct Euclidean distance, would probably create the four clusters in a similar layout to the following:
The authors point out that while conventional algorithms can do a good job of clustering based on the Euclidean distance of the points, ignoring the obstacles in the environment often renders the clustering "useless". For example, to reach the ATM marked "C11", around half of the households in that group would need to walk all the way to the bridge and then back along the river, which is to say that the ATM designated as being close to them is in practise very far away.
The goal of this paper is then to introduce and evaluate a spatial clustering algorithm that takes obstacles into account.
Concepts
In order to understand the algorithm, several simple but key concepts must be understood:
Direct distance: The direct, Euclidean distance between two points.
Obstructed distance: The length of the shortest path from one point to another, which may include deviations from the straight line due to obstacles. This is a path finding problem, which can be a difficult problem depending on the representation. The authors did not explain in any detail how to find the shortest path, and the rest of the paper simply assumes that this can be found.
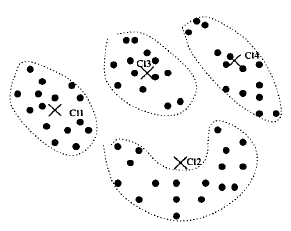
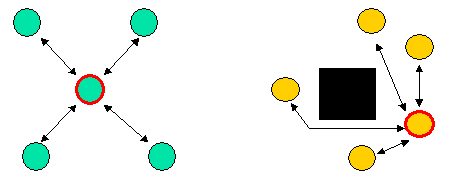
Cluster Centre: The point that is in the middle of the cluster. The authors note that either the mean location or the "medoid" can be taken. The aptly named mean location is just the point which is the mean of all the points in the cluster. The problem with this is that the mean location may be within an obstacle, as would be the case with the yellow points in the image below. The medoid is simply the point which is nearest the mean location, which solves this problem. The following image shows a couple of examples of clusters, with the black arrows showing the distance of each point to its cluster centre.
Error function: A function that can evaluate the "fitness" of a given distribution of clusters. In this paper, the error function calculated the sum of the squared distances of each point to its cluster centre. It can be thought of as the average distance of each point to its centre, so the goal of the algorithm is to minimise the value of this function.
The algorithm
The idea behind the algorithm is rather simple, and is reminiscent of a genetic algorithm which only uses mutation (i.e. no crossovers), with a population of size 1, where at each iteration a new child is created, and whoever is better out of the parent and child is kept, with the other being discarded. The algorithm can be summarised with the following pseudo-code, where the input is a collection of points and obstacles, with the object being to divide the points into k clusters:
- Randomly select k points to be the cluster centres
- Calculate current error
- Loop until cluster centres consistently stop changing
- Randomly replace one of the cluster centres with another point
- Calculate new error
- If a new error is less than current error, then keep changes and update current error, otherwise discard this new change
As you can see, it is a somewhat "blind" algorithm, which cannot guarantee to provide the optimal result. The authors do not justify the decision to use this algorithm, but it is assumed that using mathematical techniques to determine the best solution would be too computationally expensive when there were many nodes.
The algorithm is further complicated by several techniques that are used to improve efficiency. An example of such a technique is the use of "Micro-clusters", where points that are very close to each other are considered as one point. Various other pre-calculations are also used.
Evaluation
While there were a few tests given in the paper to evaluate the computational efficiency of the algorithm, there was only one example shown that displayed the algorithm's performance in terms of its clustering compared to other algorithms. In the comparison, the exact same algorithm was used, except one used direct distance when calculating the error function while the other used obstructed distance, with the intention being to show the value of taking obstacles into account when performing spatial clustering.
The scenario
The example they used for evaluation had 60,000 points in it with 10 obstacles, as shown in the following image:
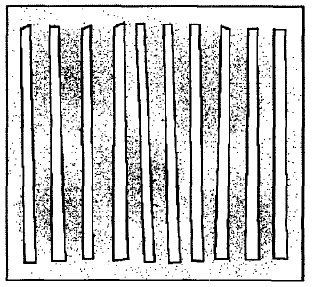
The goal of the algorithm was to cluster these points into five groups in the best way possible.
Results
The following shows the results where the obstacles were ignored:

As you can see, the algorithm would have grouped the points into five clusters in a reasonable way if there were no obstacles. However, as it is, the majority of points will need to "walk" to the end of the obstacles and back down a "corridor" to reach their cluster centre, and as a result the output of the algorithm is far from optimal.
The following image shows the results using the obstructed distance algorithm introduced in this paper:
The authors pointed out that the cluster centres were placed near the ends of corridors, rather than in the middle. This meant that for most points, their cluster centre was a lot closer than in the previous example. The errors, which can be thought of as an index rather than having real meaning, were 1.68 where obstacles were ignored and 1.24 where obstacles were considered, which shows a vast improvement when taking obstacles into account.
The authors had illustrated the importance of taking obstacles into account when performing spatial clustering.
Evaluation
Overall it was an interesting paper dealing in an interesting area. My critique of a few areas follows:
Path finding
Finding the shortest distance from a point to its cluster centre (i.e. pathfinding) is a very important and very difficult aspect in the presented algorithm. However, as noted earlier, very little was explained about how these paths were found, even though some information was given on increasing performance in this area. However, it could be argued that this paper was not about pathfinding, rather it was a general algorithm which could be used with any pathfinding technique.
Choice of algorithm
As described earlier, the algorithm was basically a genetic algorithm with mutations only and a population size of one. No explanation was given to why this algorithm was chosen, instead of, say, a conventional genetic algorithm with crossovers and larger populations, or a completely different algorithm such as one which calculated the optimal positions for the cluster centres. As it is, there is no guarantee or knowledge of how well the algorithm performs, and while we can presume that this algorithm was chosen so that it could efficiently handle large data sets, it would have been good to have some information on how well this algorithm does compared to an optimal one, and just how much more efficient this one really is.
Their conclusion
The authors tested their hypothesis that it was important to consider obstacles by using one algorithm where one ignored obstacles and one didn't. From this they concluded that it is important to consider obstacles, but wasn't this already a very obvious notion? When the difference between two algorithms is that one has an extra feature, then it's no surprise that this one will do better. In this sense then, this paper didn't really make any groundbreaking findings, but rather was more of a technical report of an implementation of spatial clustering.
Their algorithm
On a positive note, their algorithm produced a result which seemed "intelligent". In their example they gave, it would seem that the best approach would be to put each cluster centre at the end of the corridors which is exactly what their algorithm did.
In conclusion, this paper has shown that the more realistic and intelligent an algorithm is when dealing with spatial data mining, the better the results. Although sometimes it may be more difficult to model the real world realistically, there are certain features of the world, such as obstacles, which are not too hard to model but have a huge impact on the performance of the algorithm.