| Top Contents Index Glossary |
|
Link Summary |
API References External Links Glossary Terms |
This page gives you a map so you can find your way around JAXP and the associated XML APIs. The first step is to understand where JAXP fits in with respect to the major Java APIs for XML:
Now that you know where JAXP fits into the big picture, the remainder of this page discusses the JAXP APIs .
The main JAXP APIs are defined in the javax.xml.parsers package.
That package contains two vendor-neutral factory classes: SAXParserFactory
and DocumentBuilderFactory
that give you a SAXParser and a DocumentBuilder, respectively. The DocumentBuilder,
in turn, creates DOM-compliant Document
object.
The factory APIs give you the ability to plug in an XML implementation offered by another vendor without changing your source code. The implementation you get depends on the setting of the javax.xml.parsers.SAXParserFactory and javax.xml.parsers.DocumentBuilderFactory system properties. The default values (unless overridden at runtime) point to the reference implementation.
The remainder of this section shows how the different JAXP APIs work when you write an application.
As discussed in the previous section, the SAX and DOM APIs are defined by XML-DEV group and by the W3C, respectively. The libraries that define those APIs are:
The "Simple API" for XML (SAX) is the event-driven, serial-access mechanism that does element-by-element processing. The API for this level reads and writes XML to a data repository or the Web. For server-side and high-performance apps, you will want to fully understand this level. But for many applications, a minimal understanding will suffice.
The DOM API is generally an easier API to use. It provides a relatively familiar tree structure of objects. You can use the DOM API to manipulate the hierarchy of application objects it encapsulates. The DOM API is ideal for interactive applications because the entire object model is present in memory, where it can be accessed and manipulated by the user.
On the other hand, constructing the DOM requires reading the entire XML structure and holding the object tree in memory, so it is much more CPU and memory intensive. For that reason, the SAX API will tend to be preferred for server-side applications and data filters that do not require an in-memory representation of the data.
Finally, the XSLT APIs defined in javax.xml.transform let you write XML data to a file or convert it into other forms. And, as you'll see in the XSLT section, of this tutorial, you can even use it in conjunction with the SAX APIs to convert legacy data to XML.
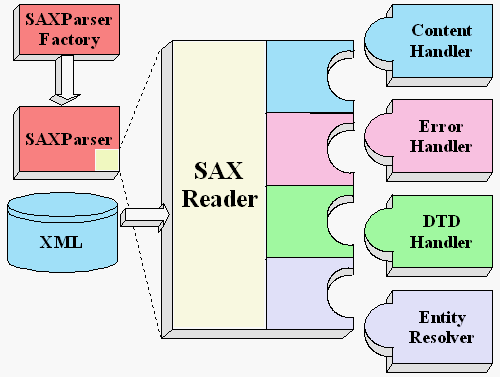 |
The basic outline of the SAX parsing APIs are shown at right. To start the
process, an instance of the SAXParserFactory classed is used to
generate an instance of the parser.
The parser wraps a SAXReader object. When the parser's parse()
method is invoked, the reader invokes one of several callback methods
implemented in the application. Those methods are defined by the interfaces
ContentHandler, ErrorHandler, DTDHandler,
and EntityResolver.
Here is a summary of the key SAX APIs:
SAXParserFactory
javax.xml.parsers.SAXParserFactory.
SAXParser
SAXParser
interface defines several kinds of parse() methods. In general, you
pass an XML data source and a DefaultHandler
object to the parser, which processes the XML and invokes the appropriate
methods in the handler object.
ContentHandler, ErrorHandler,
DTDHandler, and EntityResolver interfaces (with null
methods), so you can override only the ones you're interested in.
ContentHandler
startDocument, endDocument,
startElement, and endElement are invoked when an XML
tag is recognized. This interface also defines methods characters
and processingInstruction, which are invoked when the parser
encounters the text in an XML element or an inline processing instruction,
respectively.
ErrorHandler
error, fatalError, and
warning are invoked in response to various parsing errors. The
default error handler throws an exception for fatal errors and ignores other
errors (including validation errors). That's one reason you need to know
something about the SAX parser, even if you are using the DOM. Sometimes, the
application may be able to recover from a validation error. Other times, it
may need to generate an exception. To ensure the correct handling, you'll need
to supply your own error handler to the parser.
DTDHandler
EntityResolver
resolveEntity method is invoked when the parser must
identify data identified by a URI.
In most cases, a URI is simply a URL,
which specifies the location of a document, but in some cases the document may
be identified by a URN
-- a public identifier, or name, that is unique in the web space. The
public identifier may be specified in addition to the URL. The
EntityResolver can then use the public identifier instead of the
URL to find the document, for example to access a local copy of the document
if one exists. A typical application implements most of the ContentHandler
methods, at a minimum. Since the default implementations of the interfaces
ignore all inputs except for fatal errors, a robust implementation may want to
implement the ErrorHandler methods, as well.
The SAX parser is defined in the following packages.
| Package | Description |
| org.xml.sax | Defines the SAX interfaces. The name
"org.xml" is the package prefix that was settled on by the
group that defined the SAX API. |
| org.xml.sax.ext | Defines SAX extensions that are used when doing more sophisticated SAX processing, for example, to process a document type definitions (DTD) or to see the detailed syntax for a file. |
| org.xml.sax.helpers |
Contains helper classes that make it easier to use SAX -- for example, by defining a default handler that has null-methods for all of the interfaces, so you only need to override the ones you actually want to implement. |
| javax.xml.parsers | Defines the SAXParserFactory class which
returns the SAXParser. Also defines exception classes for reporting
errors. |
The diagram below shows the JAXP APIs in action:
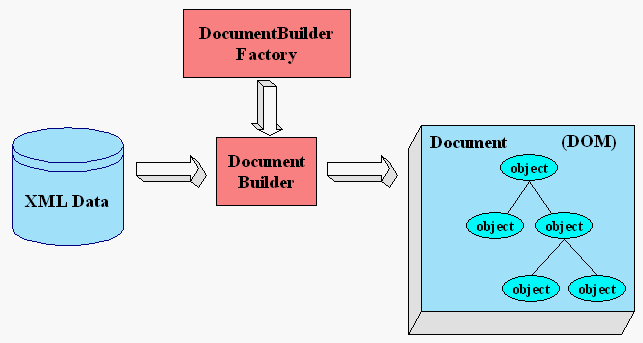
You use the javax.xml.parsers.DocumentBuilderFactory class to
get a DocumentBuilder instance, and use that to produce a Document (a DOM) that
conforms to the DOM specification. The builder you get, in fact, is determined
by the System property, javax.xml.parsers.DocumentBuilderFactory, which
selects the factory implementation that is used to produce the builder. (The
platform's default value can be overridden from the command line.)
You can also use the DocumentBuilder newDocument() method to
create an empty Document that implements the org.w3c.dom.Document
interface. Alternatively, you can use one of the builder's parse methods to
create a Document from existing XML data. The result is a DOM tree like that
shown in the diagram.
Note:
Although they are called objects, the entries in the DOM tree are actually fairly low-level data structures. For example, under every element node (which corresponds to an XML element) there is a text node which contains the name of the element tag! This issue will be explored at length in the DOM section of the tutorial, but users who are expecting objects are usually surprised to find that invoking the text() method on an element object returns nothing! For a truly object-oriented tree, see the JDOM API.
The Document Object Model implementation is defined in the following packages:
| Package | Description |
| org.w3c.dom | Defines the DOM programming interfaces for XML (and, optionally, HTML) documents, as specified by the W3C. |
| javax.xml.parsers | Defines the DocumentBuilderFactory class and the
DocumentBuilder class, which returns an object that implements the W3C
Document interface. The factory that is used to create the builder is
determined by the javax.xml.parsers system property, which can be
set from the command line or overridden when invoking the
newInstance method. This package also defines the
ParserConfigurationException class for reporting
errors. |
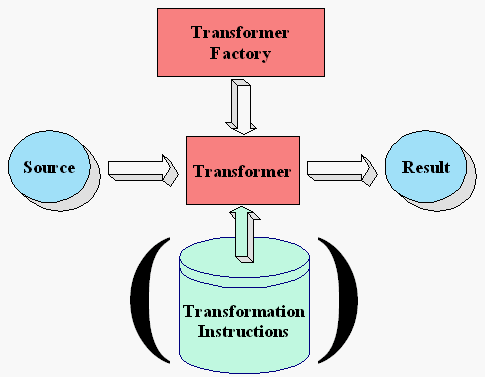 |
The diagram at right shows the XSLT APIs in action.
A TransformerFactory object is instantiated, and used to create a Transformer. The source object is the input to the transformation process. A source object can be created from SAX reader, from a DOM, or from an input stream.
Similarly, the result object is the result of the transformation process. That object can be a SAX event handler, a DOM, or an output stream.
When the transformer is created, it may be created from a set of transformation instructions, in which case the specified transformations are carried out. If it is created without any specific instructions, then the transformer object simply copies the source to the result.
The XSLT APIs are defined in the following packages:
| Package | Description |
| javax.xml.transform | Defines the TransformerFactory and Transformer classes, which you use to get a object capable of doing transformations. After creating a transformer object, you invoke its transform() method, providing it with an input (source) and output (result). |
| javax.xml.transform.dom | Classes to create input (source) and output (result) objects from a DOM. |
| javax.xml.transform.sax | Classes to create input (source) from a SAX parser and output (result) objects from a SAX event handler. |
| javax.xml.transform.stream | Classes to create input (source) and output (result) objects from an I/O stream. |
At this point, you have enough information to begin picking your own way through the JAXP libraries. Your next step from here depends on what you want to accomplish. You might want to go to:
Example Description Sample XML Files Samples the illustrate how XML files are constructed. Simple File Parsing A very short example that creates a DOM using XmlDocument's staticcreateXmlDocumentmethod and echoes it toSystem.out. Illustrates the least amount of coding necessary to read in XML data, assuming you can live with all the defaults -- for example, the default error handler, which ignores errors.Building XML Documents with DOM A program that creates a Document Object Model in memory and uses it to output an XML structure. Using SAX An application that uses the SAX API to echo the content and structure of an XML document using either the validating or non-validating parser, on either a well-formed, valid, or invalid document so you can see the difference in errors that the parsers report. Lets you set the org.xml.sax.parsersystem variable on the command line to determine the parser returned byorg.xml.sax.helpers.ParserFactory.XML Namespace Support An application that reads an XML document into a DOM and echoes its namespaces. Swing JTree Display An example that reads XML data into a DOM and populates a JTree. Text Transcoding A character set translation example. A document written with one character set is converted to another.
| Top Contents Index Glossary |